Tree Traversals
Data Structures & Algorithms
The past few posts we have been exploring Trees. We talked about what a Tree data structure is, generally, and some of the terminology common to all trees in this post. Then we dove a little deeper and implemented a Binary Search Tree (BST) in this article. Surely we now know everything there is to know about Trees, right? Not really. We could probably write a whole series of articles over the course of a year discussing the different types of Trees and the algorithms associated with them. None of that matters though, if we don’t have a way of searching through the Nodes of a Tree, which leads to the topic du jour.
A Tree Traversal is simply an algorithm that allows us to visit each Node in a Tree, once, and only once. This can be done in multiple ways, but all ways have several steps in common. For each Node in the Tree you must:
- Determine whether a left Subtree or Node exists, if so recursively traverse it.
- Determine whether a right Subtree or Node exists, if so recursively traverse it.
- Handle the Node itself.
These steps can be done in different orders and the order in which these steps are completed determine in which order the Nodes of the Tree are traversed.
Pre-Order Traversal
A pre-order traversal does the above steps in the following order:
- Handle the current Node
- Traverse the left Subtree
- Traverse the right Subtree
This is best seen in the following diagram:
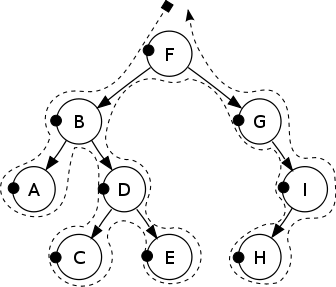
If we printed the value of each Node given the above Tree, the result would be ‘F, B, A, D, C, E, G, I, H’.
In-Order Traversal
An in-order traversal does the steps in the following order:
- Traverse the left Subtree
- Handle the current Node
- Traverse the right Subtree
Like so:

Which would result in this output: ‘A, B, C, D, E, F, G, H, I’.
Post-Order Traversal
You can probably guess in what order a post-order traversal accomplishes it’s tasks:
- Traverse the left Subtree
- Traverse the right Subtree
- Handle the current Node

Since these traversals are so similar we will not implement all of them. Instead I will implement the In-Order Traversal, and leave the rest to you for self-study if you choose. The below code assumes we are working with the BST structure we built in the last post.
def inorder(root) # Traverse left subtree if root.left inorder(root.left) end # Handle current node puts root.key # Traverse right subtree if root.right inorder(root.right) end end
There it is, easy peasy. Implementing the other two is as simple as rearranging the above code. These algorithms are known as Depth-First Searches or DFS, due to the fact that they traverse as deep into the Tree as possible before returning and going to the next sibling.
A DFS is not the only way to traverse a tree though. There is also the concept of Breadth-First Search or BFS which looks something like this:

Resulting in this output: ‘F, B, G, A, D, I, C, E, H’
This is most commonly accomplished by using a Queue to push the children onto in order to keep track of future nodes to visit. For example we would start at root node, F, and push nodes B and G onto the Queue. After we are done with F we pop off the B and push its children onto the Queue, A and D. Now G is at the top of the Queue, we pop it off and continue this process until the Queue is empty something like this:
def dfs(root) q = [root] until q.empty? # Get the first node off of the queue current_node = q.shift # Check if the current_node has children and push them onto the # back of the queue if current_node.left q.push(current_node.left) end if current_node.right q.push(current_node.right) end # Print the current node puts current_node.key end end
Good thing we covered Queues a few weeks back, eh? As you can see, fairly straightforward. We use an until loop to check if the queue is empty. Make sure to prime the queue with the root of the tree so that you don’t start with an empty queue. Then we push any children of the current Node onto the queue in order from left to right. Finally print the Node’s key value. Repeat the process until there are no more Nodes left in the Queue.
Hopefully this has shed some light on the concept of tree traversals. We have really only scratched the surface here. These concepts get more complex when we consider applying them to not just Trees but Graphs as well. Check out the links below for some further reading. Until next time.
Tree traversal - Wikipedia
Depth-first search - Wikipedia
Breadth-first search - Wikipedia